MultiMedia-TerminalBench: Evaluating Terminal Agents on Multimedia-File Tasks
A Harbor-native benchmark of 105 tasks where terminal agents must understand
audio, video, and image content and turn that evidence into verifier-checkable
file artifacts.
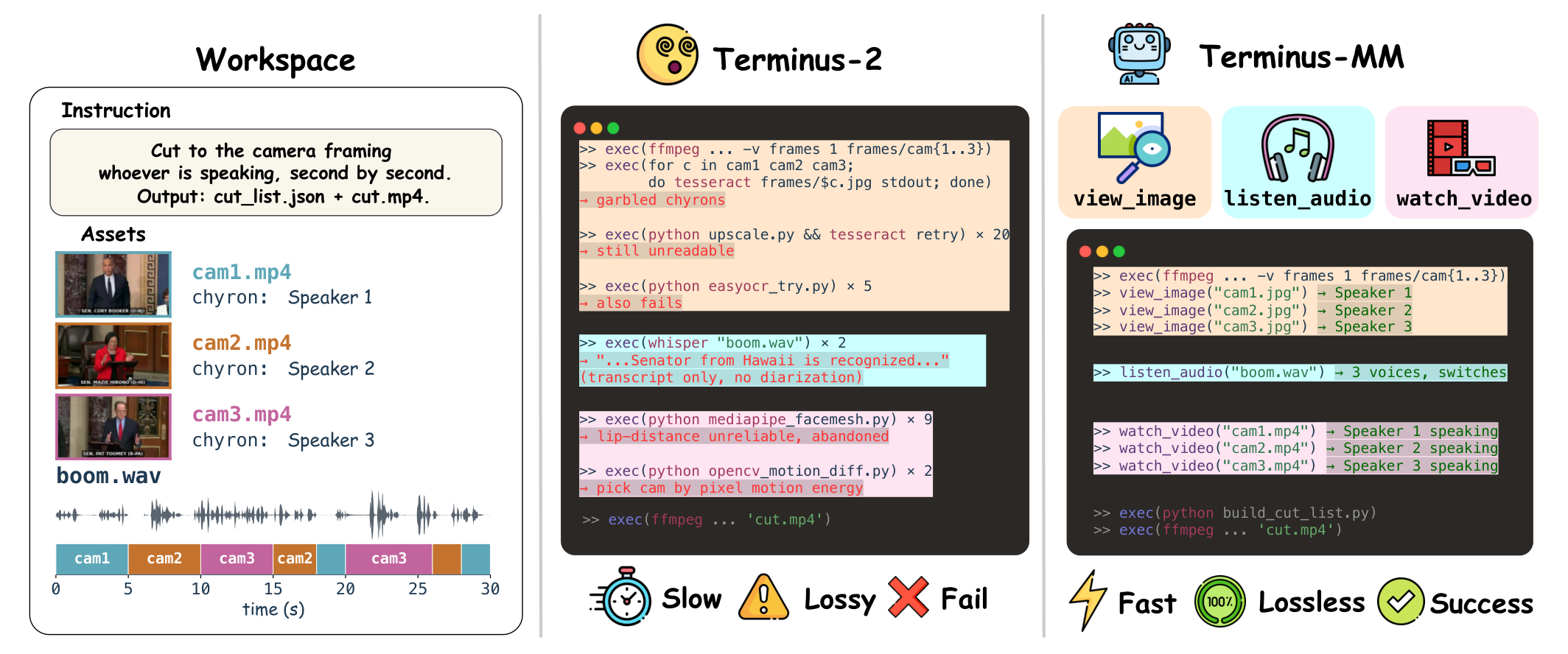
An example MMTB task and two terminal-agent approaches.
The task merges three videos and one audio file into one edited artifact.
Agents with native multimodal access read the raw files directly;
text-only agents must reach the same evidence through command-line tools
(OCR, ASR, motion-energy), adding processing steps that introduce
inefficiency and errors.
Abstract
Terminals provide a powerful interface for AI agents by exposing diverse tools for automating complex workflows,
yet existing terminal-agent benchmarks largely focus on tasks grounded in text, code, and structured files.
However, many real-world workflows require practitioners to work directly with audio and video files.
Working with such multimedia files calls for terminal agents not only to understand multimedia content,
but also to convert auditory and visual evidence across related files into appropriate actions.
To evaluate terminal agents on multimedia-file tasks, we introduce MultiMedia-TerminalBench (MMTB),
a benchmark of 105 tasks across 5 meta-categories where terminal agents directly operate with audio and video files.
Alongside MMTB, we propose Terminus-MM, a multimedia harness that extends Terminus-KIRA with
audio and video perception for terminal agents. Together, MMTB and Terminus-MM support a controlled study of
multimedia terminal agents, revealing how different forms of multimedia access shape task outcomes and determine
which evidence agents rely on to construct executable terminal workflows.
The benchmark at a glance
105
tasks
5
meta-categories
536
media files
6 h 54 m
total audio-visual content
Each MMTB task hands the agent a working directory of image, audio, or video
files and requires a checkable artifact — a selected file, a timestamped
segment, a structured JSON/CSV record, an edit list, or a processed media
clip. The expected artifact varies by task; the agent is scored only on the
final artifact at the required path, not on its rationale or command trace.
Construction pipeline. MMTB begins with 163
candidate scenarios, each anchored to a specific public URL
documenting a paid practitioner workflow —
predominantly Upwork and Fiverr gig listings, with casting calls,
practitioner forums, and industry standards documents making up the
rest — so the suite captures the multimedia work people are
actually paid to do, not synthetic instruction templates. Each scenario
is scoped into a concrete task design, scaffolded as a Harbor task, and
populated with license-compatible external media or controlled synthetic
and derivative assets. The resulting candidate tasks are then filtered
through automated checks for task structure, Docker build, media
fetching, oracle solvability, and dummy/no-op failure, as well as
baseline checks for tasks easily solved by baselines, followed by manual
review for trivial shortcuts, unrealistic setups, and redundancy. After
filtering, we obtain 105 tasks, each with asset
provenance recorded in media.toml, including source
descriptions, license information, and content hashes.
Tasks are scoped so that a typical
ffprobe → ffmpeg → frame / ASR → output shell pipeline cannot
reach the right answer without genuine cross-modal perception. Per-task
duration ranges from a few seconds to 49 min (median 1 m 20 s).
Media productionsubtitling, broadcast / film, podcast assembly, game-capture review
Performance & coachingacting takes, language-learner pronunciation, music performance feedback
Enterprise & compliancemeeting / screen-share evidence, business document structuring, audit
Personal & educationuser’s own media, lecture chaptering, study notes
Operations & researchML data annotation, smart-device automation, public-safety audits
Headline results
Standalone terminal agents struggle on MMTB: Codex CLI with GPT-5.2 solves only
16.2% of tasks. Adding native multimodal perception tools to the
agent harness lifts performance substantially, but not every modality contributes
equally. Terminus-MM — the harness that exposes
view_image, listen_audio, and watch_video —
reaches the highest binary success rate (37.1%) and partial credit (46.9%) on
Gemini 3.1 Pro.
Harness
Backbone
Native tools
Binary ↑
Partial ↑
Terminus-2
Gemini-3.1-Pro
text only
0.124
0.162
Terminus-KIRA
Gemini-3.1-Pro
+ image
0.105
0.159
Terminus-A
Gemini-3.1-Pro
+ audio
0.257
0.349
Terminus-IA
Gemini-3.1-Pro
+ image + audio
0.333
0.406
Terminus-IV
Gemini-3.1-Pro
+ image + video
0.333
0.432
Terminus-MM
Gemini-3.1-Pro
+ image + audio + video
0.371
0.469
Claude Code
Sonnet-4.6
+ image (own)
0.162
0.186
Codex CLI
GPT-5.2
+ image (own)
0.162
0.202
Mean over 105 tasks. Binary = verifier-passing artifact match. Partial = task-specific partial-credit score.
See the paper for cost, latency, modality-masking, and per-category breakdowns.
What we find
Native multimedia access improves multimedia-file task
solving. Text-only and text-image access are insufficient for
many multimedia-file tasks: on Gemini-3.1-Pro, Terminus-2 reaches
0.124 binary / 0.162 partial and Terminus-KIRA reaches 0.105 / 0.159.
Adding native media access leads to substantially higher performance:
Terminus-IA and Terminus-IV each reach 0.333 binary, and Terminus-MM
reaches 0.371 binary / 0.469 partial. Image perception is useful as a
complement to audio or video evidence, but the main bottleneck in MMTB
is access to media cues such as speech, sound events, motion, timing
boundaries, and audio-visual alignment. Native multimedia-file access
is an essential component of effective task solving in MMTB.
Command-line conversions are less efficient than native
access. When native perception for a required modality is
unavailable, agents inspect media through command-line conversion
tools. Conversion-heavy successful runs incur substantially higher
overhead: average API-cost ratios range from
1.63× to 7.72×, with worst cases reaching
30.11× when native video is missing and
42.49× when native audio is missing. Turn ratios
also increase in most settings, with a worst case of 8.10×. This
overhead stems from a longer evidence-acquisition path: the agent must
choose an intermediate representation, run the corresponding tools,
interpret lossy derived evidence, and often retry before producing the
final artifact.
Multimedia terminal harnesses need both native access and
tool-use ability. Terminus-MM and Codex CLI solve overlapping
but non-nested task sets across the 105-task suite:
28 tasks are solved only by Terminus-MM,
6 only by Codex CLI, 11 by both, and
60 by neither. Terminus-MM-only tasks tend to require
native modality understanding; Codex-CLI-only tasks tend to be cases
where command-line conversion tools are sufficient. A dedicated harness
for multimedia-file tasks therefore needs both native access and
tool-use ability. Within Terminus-MM, removing workspace-aware
modality masking lowers both binary and partial success on each
backbone, suggesting that an unmasked tool list can draw the agent into
redundant evidence gathering over unnecessary modalities.
Failure modes differ between native-media and terminal
agents. Labelling every binary-failed run across
66 Terminus-MM and 88 Codex CLI failures, Terminus-MM and Codex CLI
fail in different parts of the workflow. Terminus-MM still has a large
model-reasoning component: 47% of its failed runs end
with the model misinterpreting or misusing available evidence;
tool-operation failures (tool setup, tool execution, and tool failure
together) account for 24%. By contrast, Codex CLI
shows a much larger tool-use failure footprint: setup and execution
timeouts alone account for 39% of its failures, and
adding tool failures and low precision raises the strict tool-operation
share to about 47%. Missing native audio-video
perception forces the agent to externalize perceptual evidence through
a longer terminal pipeline.
BibTeX
@misc{heo2026mmtbevaluatingterminalagents,
title={MMTB: Evaluating Terminal Agents on Multimedia-File Tasks},
author={Chiyeong Heo and Jaechang Kim and Junhyuk Kwon and Hoyoung Kim and Dongmin Park and Jonghyun Lee and Jungseul Ok},
year={2026},
eprint={2605.10966},
archivePrefix={arXiv},
primaryClass={cs.MM},
url={https://arxiv.org/abs/2605.10966},
}